Ensuring high frontend performance in composable Next.js apps

In today's web development landscape, composable architectures are gaining popularity for their flexibility and scalability. However, this approach introduces unique performance challenges. In this article, we will explore strategies and best practices for ensuring high frontend performance in composable applications, using Open Self Service as a practical example.
Open Self Service is a new framework for building enterprise-grade frontend solutions.
Our aim is to create an open-source set of tools that would allow building not only storefronts but different client-facing frontends, with the main focus on customer self-service apps. We want to be backend-agnostic and to some extent eliminate vendor lock-in, so that the frontends you build are safe from backend changes or upgrades. Composable architecture helps us to achieve all of this, so we need to introduce it before we show you how we deal with the performance challenges we faced.
Understanding composable architecture
What is a composable architecture?
In a nutshell, composable architecture is an approach to building applications by assembling modular, independent components that work together to create a complete solution - not only in the context of frontend, but across the whole system architecture, especially backend components. In the context of Open Self Service, we implemented this architecture in the form of a framework that enables the integration of multiple API-based services to provide a seamless user experience.
At its core, a few principles characterize composable architecture:
- applications are built from discrete, interchangeable components that can be developed, deployed, and scaled independently,
- components communicate through well-defined APIs allowing for a wide flexibility in implementation details,
- decoupled systems (like frontend and backend components), which allows for each to evolve independently without affecting the other.
Composable frontends provide significant advantages - you can be quite flexible in replacing backend components without disruption, are free from vendor lock-in through multi-backend integration, and are able to adapt to changing requirements with the ability to scale specific parts based on business demands.
The separation of concerns
In building Open Self Service, we chose to implement a clear separation of concerns between different layers of the application. While there are multiple ways to achieve composable architecture, our approach focuses on:
-
complete separation of the presentation layer from the data and business logic layers, which allows each to evolve independently and enables the frontend to work seamlessly with multiple backend services
-
introduction of an intermediate API composition layer that acts as a bridge between the frontend and various backend APIs. This layer aggregates data from multiple sources and orchestrates data flows between systems. It efficiently combines static content with dynamic data while handling complex logic server-side, reducing browser processing overhead

This kind of approach ensures backend service changes don't require frontend code modifications (as long as that backend API is still backwards compatible), reducing maintenance overhead and increasing the overall flexibility.
Performance strategies
Now that we understand the architectural foundation, let's explore the specific performance strategies that make composable applications fast and responsive. These techniques leverage the modular nature of our blocks system to deliver optimal user experiences.
Leveraging server components
Probably one of the easiest "wins" is to take full advantage of Next.js server components to perform data fetching and initial rendering on the server. Each block in our system follows a clear separation between server and client components:
export const OrderDetailsServer = async ({ id, orderId }) => {
// Fetch block data from API composition layer
const data = await sdk.blocks.getOrderDetails({ id: orderId });
// Pass data to the client component
return <OrderDetailsClient id={id} {...data} />;
};
'use client';
export const OrderDetailsClient = (props) => {
// Render the actual component
return (<div>...</div>);
};
This pattern ensures that data fetching occurs on the server, reducing client-side JavaScript bundle size and eliminating client-server waterfalls. The server component fetches the necessary data and passes it to a client component that handles interactivity.
Streaming with Suspense
By using server components, we can also easily implement component-level streaming using React's Suspense, allowing parts of the page to load progressively rather than waiting for all data to be available. This approach ensures that slow-loading blocks (e.g. due to a slow or complex backend API calls) don't block the rendering of faster ones, and users can start interacting with parts of the page while others are still loading.
Strategic placement of Suspense boundaries is crucial for optimal streaming performance. In our implementation, we place these boundaries at the block level rather than at the page level, allowing for more granular control over the loading experience:
- each block has its own Suspense boundary, allowing it to stream independently
- more complex blocks can prepare the loading state to more or less represent how the component may actually look when it's ready
Let's look at the OrderDetails block that is responsible for showing the users the details of one of their orders. It consists of a title, some tiles arranged in a grid, and a list of products that were purchased.
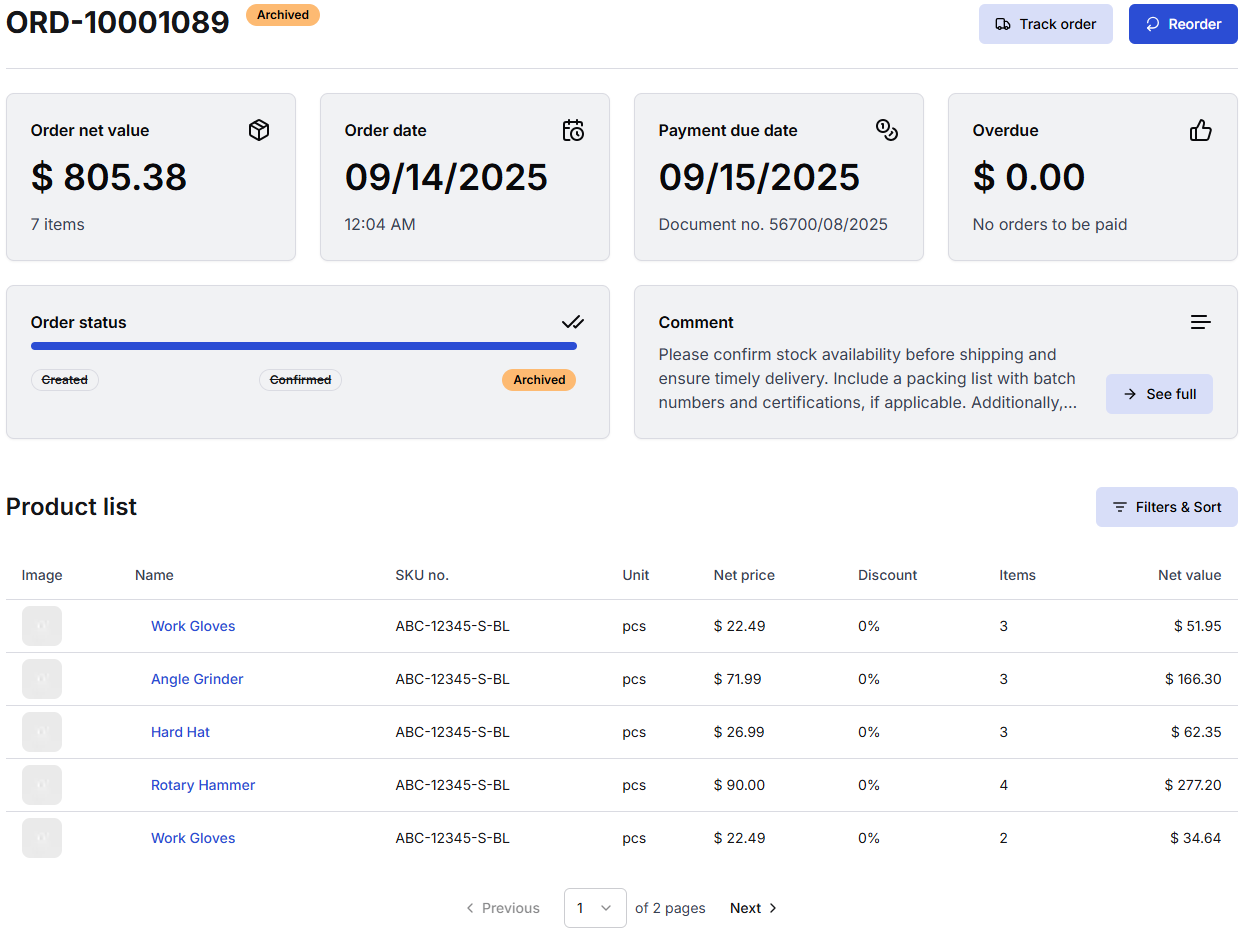
For optimal user experience - and to minimize layout shift that could occur during the page load - we prepare a similar layout in a "renderer" component that wraps the server component, using shadcn/ui's Skeleton components:
export const OrderDetailsRenderer: React.FC<OrderDetailsRendererProps> = ({ id }) => {
return (
<Suspense fallback={
// skeleton grid that represents the layout of the component
<div className="w-full flex flex-col gap-6">
<Loading bars={0} />
<div className="w-full flex flex-col md:flex-row gap-6">
<div className="w-full flex flex-col gap-6">
<div className="w-full flex flex-col md:flex-row gap-6">
<Loading bars={2} />
<Loading bars={2} />
</div>
<Loading bars={2} />
</div>
<div className="w-full flex flex-col gap-6">
<div className="w-full flex flex-col md:flex-row gap-6">
<Loading bars={2} />
<Loading bars={2} />
</div>
<Loading bars={2} />
</div>
</div>
<Loading bars={8} />
</div>
}>
// The component itself that is rendered when it's fully ready
<OrderDetailsServer id={id} />
</Suspense>
);
};
When users enter this page, they will be able to:
- see meaningful loading states while data is being fetched
- partly interact with the app (e.g. use the main navigation) even before the main content is fully ready
And once the initial HTML is prepared server-side, it is immediately streamed to the browser, which can be seen on the following (artificially slowed-down so that loading states are actually visible) video showing a single block:

Parallel data loading
By using server components, we can enable parallel data loading, where multiple blocks on a page can fetch their data simultaneously rather than sequentially. Each block is responsible for its own data fetching, and the Suspense boundaries around each block allow them to load independently:
export default function KnowledgeBasePage() {
return (
<div>
<SearchBlock />
<QuickLinksBlock />
<ArticleListBlock />
</div>
);
}
This effect is more interesting on pages that include more than one component, where each can take a different time to load (due to more complex backend logic, database access, network delays, or other causes).
Let's take a look at another example, this time a digital experience portal with a knowledge base area. Once more, each component is streamed to the browser as soon as it's ready and is then available to interact with:

While the fallback components are not sized to perfectly match their full counterparts, they don't have to be. It's enough for them to be "close enough", just so that they can be visually similar to the final rendered components, especially considering that some content will be very dynamic when it e.g. depends on a CMS configuration.
As already mentioned, using Suspense has the additional benefit of reducing Cumulative Layout Shift. Let's see what this process would look like if only one block did not provide any fallback states and notice how the article tiles "jump down" when the tiles above them appear:

While this is a mostly harmless example, just take a look at another, more dangerous example from web.dev:
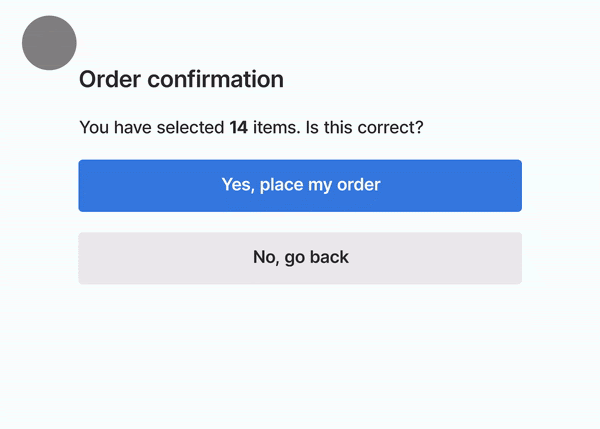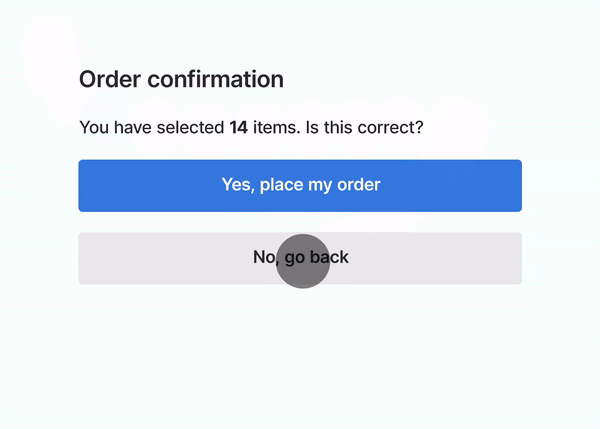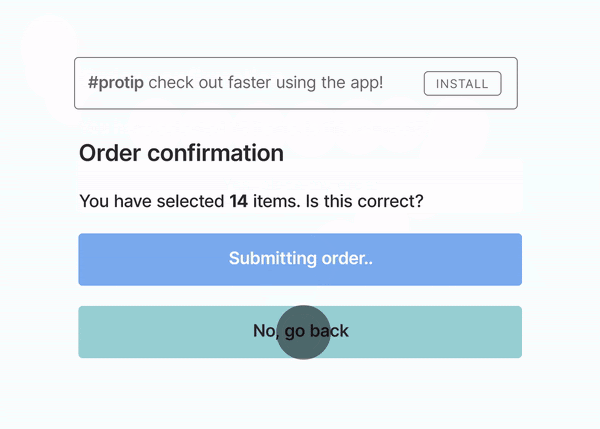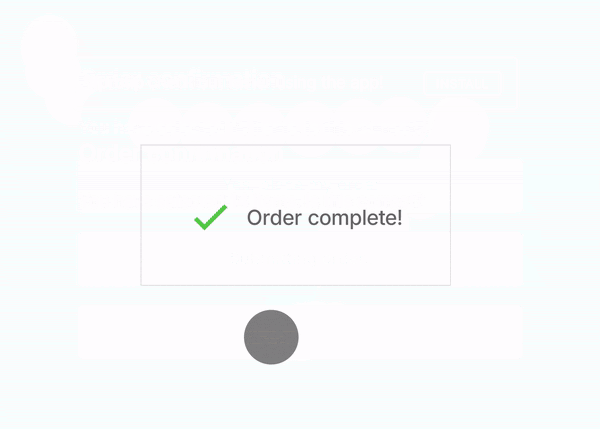
It's obvious that providing appropriate placeholders is critical not only to increase the overall performance (a high CLS will lower your Lighthouse score) but also to safeguard against potentially harmful actions.
So to sum up - this pattern eliminates the "waterfall" effect where one component must finish loading before the next one begins, significantly reducing the overall page load time. As a side effect, it can also provide a better user experience. Instead of using a single loader for the whole page or even delaying the page rendering until every single piece of data is fetched and ready for rendering, you can actually show the page loading progress.
Component-level dynamic imports
Beyond block-level code splitting, we use dynamic imports for heavy components within blocks. This is particularly beneficial, e.g., for data visualization components that rely on large third-party libraries:
'use client';
import dynamic from 'next/dynamic';
// Dynamically import the chart component to reduce initial bundle size
const StackedBarChart = dynamic(
() => import('@o2s/ui/components/Chart/StackedBarChart').then((module) => module.StackedBarChart),
);
export const PaymentsHistoryClient = ({ title, chartData }) => {
return (
<div>
<Typography>{title}</Typography>
...
<StackedBarChart chartData={chartData} />
</div>
);
};
In this example, the chart component (which depends on the recharts library) is dynamically imported only when needed (in other words, when that block is rendered on the frontend). Chart libraries are typically large and would significantly increase the initial bundle size, and typically not every page in the app will contain a chart component - so there's no point in preloading a resource-heavy library before it's actually necessary.
API composition layer
The API composition layer serves as a critical intermediary between frontend blocks and backend services. It can be implemented in a variety of different ways, but we chose to use Nest.js as a framework which fits in nicely in the whole TypeScript-based tech stack.
As an example of what we can achieve using such architecture, let's look at the service that is responsible for the endpoint for fetching data for the OrderDetails block:
// Data aggregation from multiple sources
export class OrderDetailsService {
constructor(
// Service for fetching static content e.g. from some CMS
private readonly cmsService: CMS.Service,
// Service that returns dynamic data for the user from some backend API
private readonly orderService: Orders.Service,
) {}
getOrderDetailsBlock(params, query, headers) {
const cms = this.cmsService.getOrderDetailsBlock({ ...query, locale: headers['x-locale'] });
const order = this.orderService.getOrder({ id: params.id });
// Fetch data from both sources simultaneously
return forkJoin([cms, order]).pipe(
map((order) => {
// Transform and combine data for the frontend app
return mapOrderDetails(cms, order);
}),
);
}
}
This approach provides several benefits for the overall performance. Firstly, the composition layer combines data from multiple backend services into a single, optimized response that is specifically tailored for each block - returning only the information that block needs and nothing else, which eliminates overfetching.
Instead of making multiple API calls directly from the browser (e.g. for user actions like filtering or form submissions), the composition layer handles the communication with backend services, which reduces latency and bandwidth usage. The composition layer can fetch data from multiple sources in parallel using, for example, RxJS observables, optimizing the overall response time
Additionally, raw data from various backend services is transformed into a consistent format, which does not necessarily improve performance itself but allows the frontend to be implemented in an API-agnostic way.
API-level caching
However, in a composable architecture where each block independently fetches its own data, there's a risk of redundant API calls to the same backend services. Therefore, it's important to also provide a caching mechanism that can help to reduce the load on backend services.
We chose to address this issue by leveraging Redis that can e.g. cache static CMS responses for use in other blocks. While, of course, some static content is still very block-dependant, other is shared - like general config or reusable generic translations - and can be safely cached.
In our framework, blocks don't need to implement caching logic themselves; they benefit automatically from the centralized caching system. When multiple blocks on a page require the same underlying data, the first request populates the cache, and subsequent requests are served from the cache without hitting the backend services.
Request memoization
Next.js 13 and later versions introduced an important performance optimization feature: automatic request memoization. It ensures that identical data fetching requests within the same render pass are actually called only once, significantly reducing unnecessary network calls and improving performance.
This is especially important for composable apps where the frontend does not define every page, instead relying on a CMS configuration. In such cases, there will be, for example, two identical requests needed for a single page render: one to generate metadata and the second to actually render page body:
export async function generateMetadata({ params }: Props): Promise<Metadata> {
const { locale, slug } = await params;
const { data, meta } = await sdk.modules.getPage({ slug }, locale);
return generateSeo({ data, meta });
}
export default async function Page({ params }: Props) {
const { locale, slug } = await params;
const { data } = await sdk.modules.getPage({ slug }, locale);
return (
<body>
<Header {...data.header} />
<PageTemplate slug={slug} data={data} />
<Footer {...data.footer} />
</body>
);
}
Notice that sdk.modules.getPage({ slug }, locale) is identical in both cases - request memoization will then ensure that it is called only once.
By default, the native fetch API in Next.js is automatically memoized. This means that if multiple components on the same page make identical fetch requests, Next.js will only execute the actual network request once and reuse the result for all components. This is particularly valuable in our composable architecture, where different blocks might need the same underlying data.
// In multiple server components across the page
const data = await fetch('https://api.example.com/data');
const result = await data.json();
In the example above, even if this code appears in multiple server components on the same page, the actual network request will only be made once.
However, it's important to note that while the native fetch API is supported out of the box, other HTTP client libraries may require additional configuration or adaptations to benefit from Next.js's memoization capabilities.
In our implementation, we initially used axios for API requests but later switched to ofetch, which provided a more seamless integration with Next.js's memoization system while still offering advanced features like interceptors for request/response handling. The transition was quite straightforward and didn't require too many additional adjustments:
// Our SDK implementation using ofetch
const ofetchInstance = ofetch.create({
baseURL: apiUrl,
onRequest,
onRequestError,
onResponse,
onResponseError,
});
const makeRequest = <T>(config: CompatRequestConfig): Promise<T> => {
// Configuration mapping from our standard format to ofetch format
const fetchOptions = {
method: config.method,
query: config.params,
body: config.data,
headers: config.headers,
};
return ofetchInstance(config.url, fetchOptions) as Promise<T>;
};
This approach ensures that API requests are automatically memoized when used in server components, preventing redundant network calls and improving overall application performance without requiring block developers to implement any special logic.
Image optimization
Images are often the largest assets on a page, so getting them right has an outsized impact on LCP, CLS, and bandwidth. Next.js provides powerful, safe-by-default primitives through Image component that we use across blocks, with a few conventions to keep things fast and stable.
We always provide width/height or fill to prevent layout shift and enable responsive sizing and lazy loading. Our Image component wraps next/image and only falls back to a plain <img> when dimensions are missing (prefer providing dimensions whenever possible). This is alongside with a default quality=90 that is high enough to not be noticable, but still has a noticeable impact on image weight:
export const Image: React.FC<ImageProps> = ({ src, alt = '', width, height, quality = 90, fill, priority, ...rest }) => {
if ((width && height) || fill) {
return (
<NextImage
src={src}
alt={alt}
width={width}
height={height}
quality={quality}
fill={fill}
priority={priority}
fetchPriority={priority ? 'high' : 'auto'}
{...rest}
/>
);
}
return <img src={src as string} alt={alt} />;
};
Next.js by default lazy loads images, which is great if they are below-the-fold but should be manually disabled for images that are within the initial viewport, like a hero image. We compute hasPriority only for blocks above the fold and pass it down to images within:
export const renderBlocks = async (blocks) => {
return blocks.map((block, index) => {
// decides whether the block is above the fold,
// e.g., to disable image lazy loading
const hasPriority = index < 2;
return (
<Container key={block.id}
>
{renderBlock(block, hasPriority)}
</Container>
);
});
};
Keep in mind that this "predictive algorithm", if it can be called that, is very basic and is prone to being wrong as it does not predict how large the components are. Which means that there can be situations where the third component on the page is still visible, if the first two are quite small.
This is one of the risks that come from page content being fully dependent on CMS configuration - the code cannot always predict every situation. A better, more foolproof solution would be to define the priority directly in the CMS, where app admins know how the component looks and if it is positioned above-the-fold or not - an improvement that we have in plans for the future.
Nevertheless, this flag flows into other nested components and ultimately the Image component itself, which also sets the browser fetchPriority accordingly, as shown earlier.
A good way to save on bandwidth is to set the sizes prop that matches your CSS breakpoints so the browser downloads the smallest correct candidate.
For example, for a Hero component with an image that on desktop is always no larger than 50% of the viewport and on mobile is always full width:
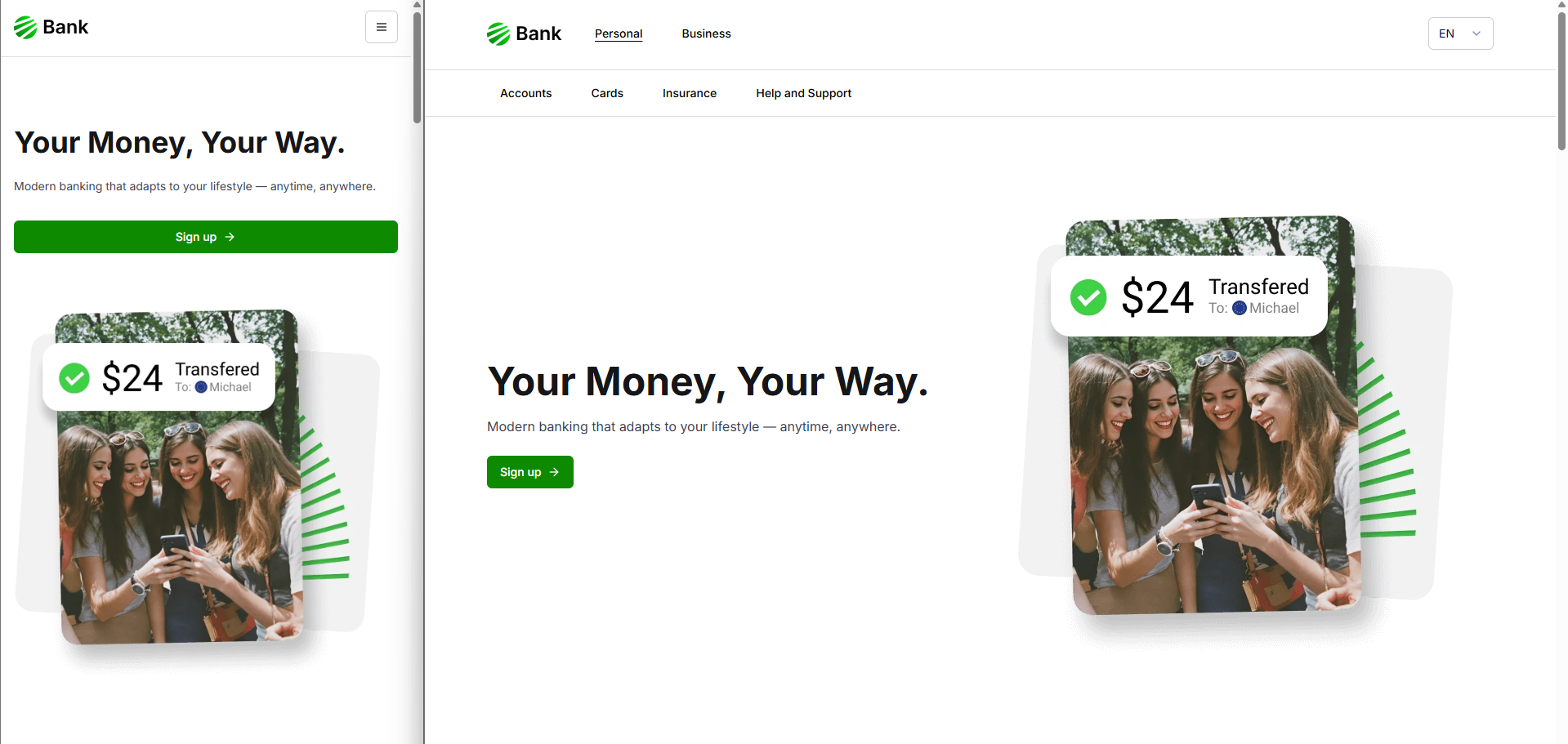
The sizes prop can be defined accordingly with media queries that match the app's breakpoints (100vw on smaller screens and 50vw on larger):
<Image
src={image.url}
alt={image.alt}
width={image.width}
height={image.height}
priority={hasPriority}
sizes="(max-width: 64rem): 100vw, 50vw"
/>
This will generate all the srcset accordingly so that the browser downloads the version that the closely matches the current viewport:
<img
alt=""
src="/_next/image?url=public/hero.png&w=3840"
sizes="(max-width: 64rem): 100vw, 50vw"
srcset="
/_next/image?url=public/hero.png&w=384 384w,
/_next/image?url=public/hero.png&w=640 640w,
/_next/image?url=public/hero.png&w=750 750w,
/_next/image?url=public/hero.png&w=828 828w,
/_next/image?url=public/hero.png&w=1080 1080w,
/_next/image?url=public/hero.png&w=1200 1200w,
/_next/image?url=public/hero.png&w=1920 1920w,
/_next/image?url=public/hero.png&w=2048 2048w,
/_next/image?url=public/hero.png&w=3840 3840w
"
/>
This output is based on deviceSizes config that you can also adjust to your own needs. For example, you might want to narrow down the list of possible viewports if your app is very image-heavy to simply save on the amount of HTML generated:
deviceSizes: [430, 828, 1200, 2048, 3840];
At the end it's quite critical to monitor LCP and preloads in Lighthouse and check if it's possible to adjust the priority if you see that lazy loading:
- does not occur on images below-the-fold
- or it does occur for images above-the-fold
Conclusion
Building high-performance composable frontends requires addressing challenges across multiple architectural levels. The approach we've described combines modular architecture with Next.js server components for efficient rendering, strategic Suspense boundaries for progressive loading, and an API composition layer that optimizes data flow. We further enhance performance through caching, request memoization, and component-level dynamic imports.
These strategies deliver real benefits: faster page loads, smoother interactions, and responsive applications even under challenging network conditions. For developers, the composable approach improves maintainability, simplifies testing, and allows independent evolution of different application parts.
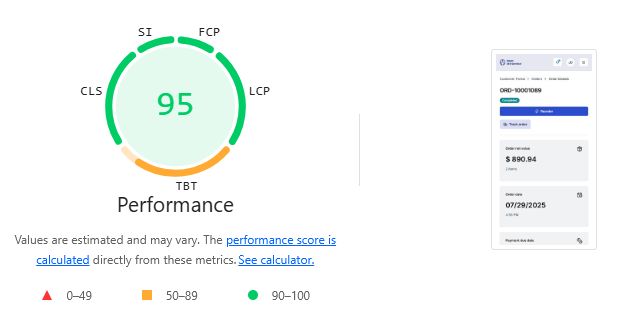
As shown in the Lighthouse performance audits, these optimizations result in excellent scores across all Core Web Vitals and performance metrics:
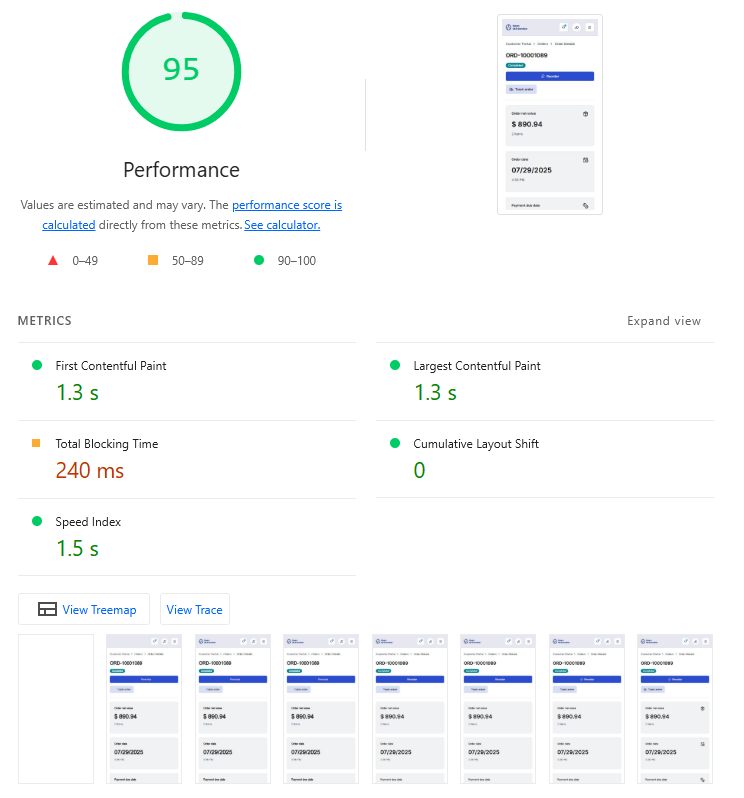
The Open Self Service framework demonstrates this in practice, providing a foundation for building performant composable applications that scale with business needs while delivering exceptional user experiences. This approach is particularly effective in enterprise environments where complex integration requirements, high traffic, and demanding performance standards are common. Open Self Service delivers outstanding results by enabling organizations to build fast, maintainable frontends that seamlessly integrate with multiple backend systems while achieving superior performance metrics.
Want to see it in action?